摘要:ChatGPT凭借NLP生成对文本指令的响应,推动了通用人工智能的跨越式发展。作为辅助创新工具,ChatGPT能够对复杂的提问做出细微的、逻辑严密的回答,节省了学术工作者为知识创意所支付的人力成本。但ChatGPT这种便捷性给学术出版带来一系列问题——创作临界值的改变导致作者身份归因困难,AI捏造消解学术权威性,AI依赖掣肘学术创新,AI偏见承接威胁学术严谨性。文章提出,面对技术带来的挑战,知识正义的维护不能仅依赖超级虚拟辅助工具,而应由学术共同体一起努力,期刊、作者、审稿专家等都需分担责任,应采取分布式问责的方式,对AI学术辅助进行合理部署和伦理约束,使得学术社区标准能够支撑更加公平、公正、具有生产活力的学术实践。
关键词:ChatGPT;学术出版;知识合规;作者身份;AI依赖
OpenAI成立于2015年,是一家专注于AI产品开发的研究实验室,获得了马斯克、微软公司等支持。2022年11月30日,OpenAI推出ChatGPT(Chat Generative Pre-trained Transformer),立即在广泛的社会范围引起关注,成为当今最强大的AI处理模型之一,在不同领域的应用日益增长,人机交互技术迈向了通用人工智能的阶段,从感知智能进入认知智能时代。
GPT起源于自然语言处理(NLP)领域,这是一个专注于使机器能够理解和生成人类语言的人工智能领域。ChatGPT是生成式的大规模语言模型,以生成式的自监督学习为基础,从太字节(Terabyte)级训练数据中学习隐含的语言规律和模式,凭借NLP生成对文本指令的响应,推动了NLP的跨越式发展。ChatGPT成功通过了研究生的商业和法律考试,可以用来撰写小文章,其质量甚至能够超过博士生的平均水平,被认为是一种颠覆式的创新。这种基于数据驱动的应用正在进入学术出版领域,成为一股不易被识别的知识暗流(tacit knowledge),可能会彻底改变学术出版。
1 ChatGPT发展历程
与性能:模型泛化中的知识调度
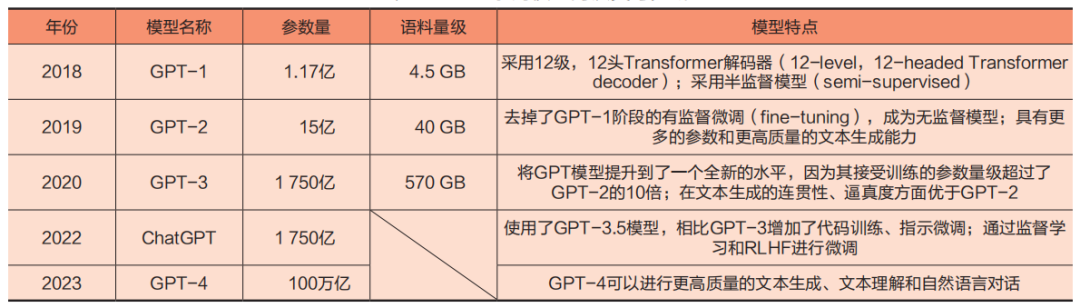
人工智能(AI)和自然语言处理(NLP)的快速发展促进了多功能语言模型的广泛应用。其中,GPT模型擅长于对网页、图书、社交媒体文本等海量文本数据进行预训练,对文本中的词汇、短语机器关系和模式进行学习和分类。GPT能够实现强大的语言模型创建功能,具体涵盖GPT-1、GPT-2、GPT-3、GPT-3.5、GPT-4等。从GPT-1到GPT-4,GPT生成连贯文本的能力在逐渐提升,对语言特征的捕捉更为精准,能够在各种复杂领域进行知识组合和演绎推理,对下游任务的完成度也更加出色,GPT系列模型的演变与更新如表1所示。ChatGPT基于GPT-3.5架构,在自然语言处理中拥有出色表现,可以进行语言理解、文本生成和机器翻译。其主要架构于Transformer算法之上,Transformer算法是使用超大规模数据来完成日常训练的神经网络深度学习算法,它克服了循环神经网络(RNN)、卷积神经网络(CNN)等NLP模型从序列到序列的局限性,可以创建高效且可扩展的语言模型,调用千亿级别的参数,具有很好的“时序数据处理”(理解上下文关系)和“自注意力机制”(抓重点、找联系)的能力。
表1 GPT系列模型的演变与更新
自我学习是人工智能的关键组成部分,允许系统通过经验和数据获取新信息,并改进基于知识的判断和结论。机器学习(ML)是ChatGPT的重要组成部分,因为它允许系统从数据中学习,并随着时间的推移逐渐提高语言处理能力,从而实现人机之间更有效的沟通和交互。机器学习模型对通用能力有所掌握后,将其泛化到其他场景和指令中,其所依赖的模型和数据不断堆积累加时,模型对人类世界运作规律的辨识率与模仿率会随之累加,这也是为什么ChatGPT一推出就火热的主要原因。“如果说上一次让AI火出圈的AlphaGo所展现出的是在特定领域的‘专’,这一次ChatGPT展现出的则是AI在广泛应用场景的‘通’:这个“通”以正常人都会、都懂、都能体验的对话形式呈现,让AI——特别是自然语言处理技术进入主流用户群,孕育出了这一现象级产品”
ChatGPT在通用人工智能领域取得了突破,在多重场景中表现出比普通劳动者更大的优势,其发展带来的“技术性失业潮”让人们不得不审视人工智能带给人类社会的深刻影响。ChatGPT从海量数据中提炼、总结规律模型,这种能力在过去被认为只有人类才具备,而狗、鸟等动物只具备简单的归纳、学习能力。原本人类作为“万物之灵”是这个世界上仅有的复杂思考者,而如今机器的理解、学习和创新能力被无限放大甚至超越了人类自身,ChatGPT的出现昭示着另类竞争者的降临。工业时代的机械创造是对人类体力劳动的解放,将人从枯燥的、繁重的流水线中解放出来,提高了生产效率;而人工智能的发展则将人从初级的脑力劳动中解放出来,让人们可以投入更具创造性的工作中。长远来看,人工智能甚至是对人类思维意识的一种替代性颠覆,使得“人类无用”的价值凸显。人类优越感的消解以及日后人与机器的差距或许还将进一步扩大,这缘于二者的进化路径迥异,自然人的养成需要经历十多年的成长、教育,需要投入大量的人力、物力,而人工智能的进化基于天文数字一样的数据参数,能够进行自我的改进、独立学习,在之前的基础上不断迭代,而不需要像人一样从婴孩时代培养。对于用户来说,ChatGPT最大的魅力在于,它不仅能够承担一些辅助性的、基础性的工作,更能够在一些创造性的领域生成让人满意的内容,由此为人们争取了更多的自由时间投入自己喜欢的、更具创造性的领域,ChatGPT对于学术工作者来说是非常诱人的辅助工具。
2 ChatGPT在学术研究中的辅助创新
人工智能模型可以从大量的数据中获得一定的模式和结构来实现新数据的输出和创建,这是生成式AI的(Generative AI)的底层技术逻辑。诺伯特·维纳(Norbert Wiener)发展出了一种关于人类本质和社会的“控制论观点”,强调我们可以从事物的结构本身获得什么,同样的,对于ChatGPT这种新兴技术架构本身来说,我们关注的不是这种技术架构本身是如何搭建的,而是我们从这种架构中可以获得什么。ChatGPT在多领域、多场景中受到追捧,原因在于人们可以通过其获得高质量的、类人化的智能生成效应,例如,其可以用于财务报表的生成、法律文书的撰写、合同审查、投资管理、情感分析、创协写作、代码调试、脚本生成,等等。ChatGPT作为一个辅助创新工具,利用数据知识进行回应,输出连贯的、跨领域的文本内容,对复杂的提问做出细微的、逻辑严密的回答,甚至可以根据专业人士自身的需求进行差异化的定制服务,这些功能用于学术研究和出版是十分令人兴奋的。在传统的学术研究中,学术工作者要想在专业化、模式化、流程化的工业化生产方式之外获得创造性突破,完成知识萃取,需要投入大量的时间、精力与脑力,属于手工原始积累阶段。ChatGPT的出现大大提升了人们对知识的合并、组织、扩展的能力,机器模型类人化的推理、对话和总结使得知识的社会价值进一步外溢,科研人员借助ChatGPT强大的自然语言处理能力,完成基础性甚至是创造性的工作,大大节省了其为知识创意所支付的人力成本,人类知识积累的范式发生了改变。
ChatGPT在学术研究中的辅助创新方式是多维度的,贯穿于整个创作流程中。第一,ChatGPT可以根据特定主题,为研究人员提供选题方向、论文大纲和参考文献,为学术工作者提供最新的科研成果和文献,成为有效的学术搜索引擎。例如,ChatGPT的衍生品ChatPDF,是Mathis Lichtenberge开发的一款应用,用户将文献的PDF上传后,它可以提取并归纳文献的核心观点,大大提升了文献阅读效率,能够帮助学术审稿人快速抓住文章核心要点和创新点。第二,ChatGPT能够进行顺畅对话的语种超过数百种,包括中文、英语、日语、汉语、西班牙语、德语等,覆盖全球大部分国家和地区的语言,可以为学者提供翻译服务,进行线上的实时翻译,移除不同国别研究人员的语言障碍。第三,ChatGPT可以进行论文草稿的搭建或文本的生成。但目前来看ChatGPT还不具备产生符合期刊要求的原创研究的能力,而更适合用于文献综述、评述性文章、总结性报告的写作。第四,ChatGPT可以进行数据分析、情感分析,对论文稿件中不完善的用语进行调整和修改。第五,ChatGPT可以扮演虚拟导师的角色,为学者提供学术发展规划与路径。概括来讲,ChatGPT根据用户输入内容进行上下文的结合与理解,在此基础上完成多任务处理。在学术研究工作中,ChatGPT可能完成的辅助性任务包括:翻译、简洁呈现研究结果、文本生成、提炼摘要、上下文理解、数据分析等,其在推理、对话和总结方面的突出表现,可充分满足人们在短时间内低成本获取密集知识的需求。
ChatGPT在学术研究中引入了知识暗流,模糊了学术创作的边界。西北大学的研究人员要求ChatGPT根据医学期刊上的论文撰写50个医学研究摘要,然后邀请研究人员进行识别,人类审稿人能够正确识别68%的机创内容和86%的真正摘要。这说明ChatGPT与真实作者的创作边界已不是那么清晰可辨,学术审稿人很难完全准确识别出ChatGPT生产的内容。ChatGPT并没有产生新的知识,而是对已有内容进行归纳与重组,生成了新的部落知识,知识只是发生了形式的迁移,并没有实质的增量。对于个体来说,往往更关注技术带来的直接利益,而非更下游的影响,所以有学者认为学术研究中ChatGPT这种AI工具的应用,本质上属于“高科技剽窃”(high-tech plagiarism)和“学习逃避”(a way of avoiding learning)。当这些高度类人化的机创内容被不加思考、不加核实地挪用时,表面上看,ChatGPT成为了科研人员更有效地组织知识的辅助工具,提升效率的同时使得学者与竞争者拉开了距离;但实质上,这加剧了学术不公平,对学术的权威性、专业性、创新性都会造成某种程度的消解。所以,人们在关注技术便捷的同时,也应该重新审视和评估AI扩散对学术研究和学术出版带来的可能威胁。
3 ChatGPT给学术出版带来的挑战
ChatGPT进入学术出版领域,可帮助作者、期刊和审稿人等承担很多工作,为他们腾出精力完成其他任务,但伴随技术便捷而来的是作者身份归因难、内容失实、AI依赖、AI偏见等问题,对学术出版造成了深刻的影响。
3.1作者身份归因困难与创作临界值的改变
作者身份有两方面的意义,一方面是对做出实质性智力支持与智力付出的参与者给与身份认可,另一方面作者也是对发表内容进行责任归属的承担人。在ChatGPT使人机创作临界值发生改变的情况下,应该如何框定ChatGPT在学术研究、学术出版中的边界呢?首先需要回答的问题便是,ChatGPT是否可以成为共同作者?是否可以参与学术论文写作?国内法学专家倾向于认为ChatGPT作为著作权人仍无法完全成立,并不具有作者身份。根据我国《著作权法》第十一条,虽然允许拟制法人或者非法人组织成为作者,但其并不具备真正的创作力,“即使是那些通过立法承认人工智能生成内容可以获得著作权保护的国家,通常也是将计算机软件的开发者,或者是将在生成内容过程中作出实质性贡献的人认定为作者”。那么,ChatGPT在成文过程中如果扮演了实质性的贡献角色,是否可以获得共同作者的身份?学者们看法不一,有的学者认为如果在策划或撰写过程中ChatGPT提供了帮助,则应该列为作者,以对其贡献给与认可,目前已有一些文章将ChatGPT列为合著者(如ChatGPT and Zhavoronkov,2022;King,2023;O’Connor and ChatGPT,2023)。
除了ChatGPT并未产生新的知识,只是对网络上的信息进行了重新整合与挪用,还有一个问题是ChatGPT无法满足相应的问责。ChatGPT作为非法律实体,不能管理版权和许可协议,不能以有意义的方式承担责任,不具备作者身份的获得条件。作为辅助性工具,ChatGPT无法进行反思、推理和充分论证,而是利用互联网海量数据训练出来的,这使得对来源的追踪、对责任人的归属变得不具有现实性,于是作者在学术写作中引用ChatGPT所提供的内容的那刻起,侵权风险便从模型转嫁到了作者自身。某种程度上,作者的不合规引用构成了剽窃。对剽窃的定义,不止局限在文字的复制与抄袭,对他人观点、创意、图形、方法及其他任何智力产品的挪用都属于其范畴。通过ChatGPT获取思路与启发,尚且并不完全等同于剽窃,如果作者对机创内容进行了说明与标识,也并不完全属于抄袭。但是,完全以知识暗流的方式,将机创内容融入自身的论述中,就属于学术不端的范畴。这也是为什么一些期刊、机构拒绝承认ChatGPT的合著者身份,例如《科学》(Science)和《自然》(Nature)禁止在期刊发表的论文中使用ChatGPT以及其他自动生成式工具生成的任何文本,拒绝的理由是ChatGPT无法对其作品承担相关的问责。不少期刊委员会都出台了关于学术出版中使用大型语言模型的政策,例如在COPE(出版伦理委员会)、ICMJE(国际医学杂志编辑委员会)关于作者身份的相关说明中,明确提出人工智能工具无法满足作者身份的要求,因为它们不能对提交的作品负责,因此不能被列为合著者。
对于ChatGPT作者身份归因的问题,笔者持保留态度,对于智能工具的问责需要从长远角度看,正如Polonsky和Rotman所说,未来随着AI的完善和增强,或许可以成为版权协议的管理者、成为利益冲突的分辨者,可以满足作者身份的要求成为论文的合作者,只不过需要明确的披露,标注使用了哪种AI工具以及如何使用,充分而完善的引用来源说明不仅是对他人产出的尊重,也确保了学术研究的规范性与完整性。
3.2机器捏造对学术权威性的消解
ChatGPT基于人类语言数据库而生成、模仿人类对话的应用程序,根据给定的文本提示给出类人的答案,其热度颇高,有很大一部分原因在于ChatGPT能够在专业、智慧、对话等方面与人类表现出高度相似的特征。但ChatGPT表现的“足智多谋”并非无条件,它生成的高质量观念取决于高质量的提问,在没有得到足够提示的情况下,ChatGPT只会给出非常简洁甚至肤浅的回答,而且由于其数据并非及时更新的流动数据,所以学者们在使用过程中可能产生认知误差或获得虚假信息。例如,以下为笔者于2023年5月8日上午,向ChatGPT(基于GPT-3.5模型)的提问,ChatGPT给出的回答非常简单,且错误百出,将GPT-3.5模型回答为GPT-2。
■提问:请用谷歌学术的风格,向我介绍一下什么是OpenAI,什么是ChatGPT(2023/5/8上午11:19:28)
■ChatGPT给出的回复:
什么是OpenAI
OpenAI是一个人工智能非营利组织,旨在通过无歧义、有利于所有人的方式开发人工智能。该组织成立于2015年,由伊隆·马斯克、山姆·阿尔特曼等创建。OpenAI在公开平台上共享了大量人工智能研究成果和代码,旨在促进人工智能的发展和普及。
什么是ChatGPT
ChatGPT是OpenAI基于GPT-2模型创建的一种用于智能聊天的系统。GPT-2是一种自然语言处理模型,它的训练数据来自于大量的网页内容。ChatGPT基于该模型,使用人工智能技术帮助用户完成各种任务,如回答问题、聊天等。该系统能够提供高质量的自然语言输出,与普通聊天机器人相比,在回答问题时更加详细,更加接近人的思维方式。
笔者将同一问题投喂给ChatGPT(基于GPT-4模型),其对问题的理解更加到位,给出的问题更符合要求,可以生成学术风格的文本,如图1所示。

图1对同一问题的回答,GPT-4模型明显优于GPT-3.5模型
AI生成内容对学术研究的严谨性、科学性、专业性来说是一种威胁。主要问题在于内容低质化,对某一领域的知识缺乏深度产出。有些时候,ChatGPT非常擅长“胡说”,笔者曾经输入指令要求ChatGPT推荐关于“算法问责”的文献,并提问这些文献是否为真实发表,ChatGPT给出肯定答复,但事实上这些文献都是ChatGPT捏造出来的。类似地,有编辑要求ChatGPT提供果皮在高温情况下是如何降解的,ChatGPT给出的10个引文几乎每个都是伪造的。这与模型在初期标注体系不够完善和规范有关,而且其模型训练的语言主要为英语,可能会因为语言环境的切换而导致信息有所流失和失误。虽然ChatGPT接受了海量数据的训练,但是不可避免地存在各种瑕疵,在学术出版中需要以更加审慎的态度对待。
3.3 AI依赖对学术创新的掣肘
学术研究的目标在于使人类对世界有更清晰的理解并更好地发展。ChatGPT虽然能够依据研究人员的需求进行内容生成,提升研究效率,但也对科研工作中的创新和反思形成遏制。ChatGPT对知识的计算糅合并没有明确的引用过程,人们可能会在学术创作中存在一种引用机创内容而不会被发现的侥幸心理,以功利化的方式使用机创工具,依赖自动化工具代替重复性劳动的同时,依赖AI作为观点的来源,这种依赖可能会导致对AI生成工具的滥用,如垃圾邮件的创建、深度伪造内容等。在没有完全理解ChatGPT提供内容的基础上,在没有付出任何努力的情况下,依赖AI生成工具就可以提交一份学术论述,人们由此丧失独立思考和批判思维的能力,人类知识价值的创造被知识的计算价值所替代。虽然很难通过强制规避的方式阻止ChatGPT的使用,但如何使ChatGPT对学术创新的吞噬降到最低,如何鼓励更多的道德实践,使其成为学术创新中锦上添花的工具,仍然是学术共同体需要思考的问题。
3.4偏见承接对学术严谨性的破坏
ChatGPT训练数据的不确定性和不透明性,导致其可能承接训练数据的偏见,或者遭遇对抗性的恶意输入,这些都是比较致命的局限。例如,ChatGPT可能受到一些主流内容的影响,而忽略一些小众的、边缘的、值得被关注的新兴内容;ChatGPT训练数据可能刻意凸显某些内容和偏好,其推荐的结果或数据源可能并非最新研究成果,导致其生成的内容过时;ChatGPT也面临着被攻击和恶意诱导的风险,有人借助恶意指令的输入,躲避ChatGPT的安全机制,诱导ChatGPT执行意外动作,如进行洗稿活动等。对于学术研究来说,基于这些有缺陷的数据所形成的结论和决策,无疑会挑战学术的严谨性和权威性,损害作者个人的学术信誉度。
4人机协作中知识正义的维护与学术智能的实现
“我们倾向于高估新兴技术在短期内的影响,而从长远来看低估其影响。”(We overestimate the impact of technology in the short-term and underestimate the effect in the long run.)这是1960年代未来主义学者Roy Amara作出的著名论断。ChatGPT作为通用人工智能(AGI)和通用目的技术(GPTs)发展的里程碑,颠覆了以内容为中心的传统大众传播模式和以用户为中心的社交媒体传播模式,迎来了以数据和算法驱动的“暗网式”大集市传播模式,是一次社会权力的再转移和再分配。虽然ChatGPT给人耳目一新的颠覆式认知,但其尚不具备完全的人类智能。未来还将会有大量的智能语言模型在精进,AI的不断完善与扩散在人类进化中会扮演重要角色。随着训练数据量级的不断膨胀,人工智能会超出人类提取意义核心的能力范畴,成为一种更高阶的自动化工具。这种工具将会进一步的改变人类的兴趣结构,改变我们思考的事物,通过改变我们用来思考的东西,进一步改变我们的符号属性,新技术通过改变思想发生的舞台而改变了社区本质。1981年《渥太华公民报》(The Ottawa Citizen)中有一篇文章《教师必须与计算机斗争》(Teachers must fight computers)写道:“如果教师不去抵制越来越多出现在教室中的计算机,识字素养可能会在10年内消失。”对于新技术的恐惧一直都有,尤其是人们担心技术对现有的知识体系造成冲击,但是面对技术带来挑战的时刻,也正是重新审视学术社区的时刻。
为了保证学术研究的质量,杜绝或防止学术不平等现象,对ChatGPT的应用应采取分布式问责(a distributed accountability)的方式展开,期刊、作者、审稿专家都需要分担责任。对于学术出版机构和期刊来说,需要有接受新兴技术的勇气,包括抓住技术进步带来的机遇,尝试解决其带来的问题;对新兴事物保持开放的态度,吸纳对学术生产可能会起推动作用的技术工具,根据技术条件的发展与成熟而不断调整期刊行动与规定,在工具采纳的过程中对可能存在的问题进行明智的审议。虽然目前ChatGPT未在国内大范围用于学术出版,但是对于出版机构来说,依然要持续观察,保持警惕,对AI工具的使用作出相应的引导,在透明度、问责制、版权保护等方面作出相应的说明与指导。面对可能的高科技剽窃,期刊成为了维护数据正义(data justice)的一环,学术期刊可以采用一些反GPT的软件来检测机创论文,例如GPTZero、Originality.ai、Plagibot都能够对GPT生成的内容依据相似性给出判断。AI的扩散可能会要求审稿人提高对学术生产评估的审查,优质论文的评估标准或许会发生变化。对于作者来说,有必要也有义务进一步验证AI工具提供的内容的真实性、有效性,明确标识哪些内容是由ChatGPT产生的,并通过何种提示得到的相应文本,对AI工具的可及性做出解释,并确保AI内容的准确性。
5结语
目前ChatGPT对学术出版的影响并未深刻显现,但生成式AI对学术实践的影响会在日后日益凸显,其伦理意义是当下不得不思考的问题。虽然ChatGPT的便捷性、智能化、可得性、易用性大大提升了学术产出的效率,但作者身份和版权归属、变相剽窃、低质化输出、数据偏见承接等问题与学术研究息息相关。另外,ChatGPT并非完全免费,基于GPT-3.5模型每千字(1个汉字=2tokens,1个英文=1 token)收费0.002美元,基于GPT-4模型每千字收费0.03—0.06美元,商业平台的逐利性推广意味着并非所有地区的所有人都可以负担得起ChatGPT的访问成本,这无形中会扩大不同地区、不同群体之间的学术差距。知识传播的民主化与大众化并不能完全依赖技术实现,正如知识正义的维护不能仅依赖超级虚拟辅助工具,而应由学术共同体一起努力。对于期刊、审稿人、作者和AI开发者在智能学术中的实践,需要更新的政策框架进行规范,从不同的主体视角鼓励人机协作中高质量数据集的采纳和创新性内容的生产,通过不同主体的自我规范以及期刊、出版行业的共同协作,对AI学术辅助进行合理部署和伦理约束,使得学术社区标准能够支撑更加公平、公正、具有生产活力的学术实践。未来,随着机器算力的提升,生成式AI会持续完善,弥补现有不足,其对学术出版的潜力是值得期待的,在吸纳其优质因素的同时,通过合规实践避免其负面影响,使得AI技术能够为人类核心价值观的实现而服务,而非作为取代人的存在而存在。